Character Calculation
During scanning, once the characters are broken into individual objects, they need to be sorted, sectioned, and calculated. This whole process isn’t very complex in and of itself.
Sorting
First, the characters need to be sorted. This is a process unknown to training as the format of the training file insures all characters will be in the same line perfectly. In scanning an image, not all characters will be exactly aligned, so they need to be put in a line. At the beginning of scanning, the lines characters were in were separated, so this step
Character Segmentation
First, the character is broken up into 16 pieces, These pieces are not pixel based, but percentage based to keep it scalable among multiple font sizes, as fonts carry the same proportions when scaling up/down.
A visual of what the sections look like and their index of the value array (Which will be used later) can be found here:
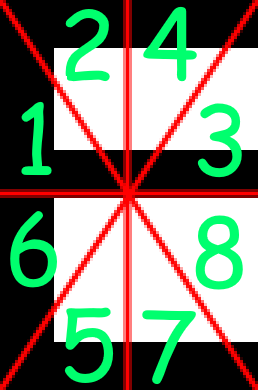
After that process has occurred, the second sectioning process starts. This one is more simple, in that

Applying The Sections
After the sections and their indices have been established,
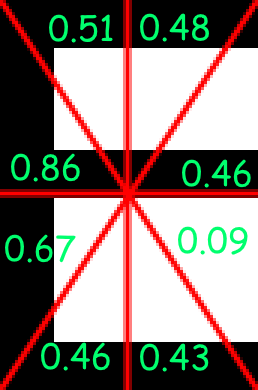

With the indices applied, the value array would be:
[0.86, 0.51, 0.46, 0.48, 0.46, 0.67, 0.43, 0.09, 0.77, 0.37, 0.37, 0.77, 0.36, 0.36, 0.77, 0.37, 0.37]
Character Matching
After the array of 16 data points are calculated, it’s time to
After these differences are calculated, a closest character still needs to be chosen. If the matching character was chosen just based on these data points, characters being primarily black such as ., ,, |, -, parts of an =, !, ?, and several more would all be detected as each other, as the sizes of these characters have not been taken into account.
With all characters’ differences mapped to their database characters being iterated over, the database character’s average width is divided by its average height, which then in turn has the input character’s width/height value subtracted from it. This value is then multiplied by the size ratio weight from OCROptions#setSizeRatioWeight(double)