Character Calculation
Arguably the most important step in the OCR, the system next needs to derive the data it’s going to store in the database.
Character Segmentation
First, the character is broken up into 16 pieces, These pieces are not pixel based, but percentage based to keep it scalable among multiple font sizes, as fonts carry the same proportions when scaling up/down.
A visual of what the sections look like and their index of the value array (Which will be used later) can be found here:
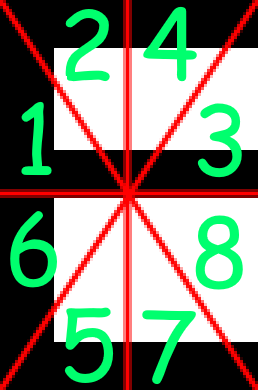
After that process has occurred, the second sectioning process starts. This one is more simple, in that

Applying The Sections
After the sections and their indices have been established,
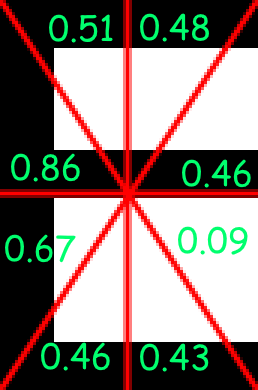

With the indices applied, the value array would be:
[0.86, 0.51, 0.46, 0.48, 0.46, 0.67, 0.43, 0.09, 0.77, 0.37, 0.37, 0.77, 0.36, 0.36, 0.77, 0.37, 0.37]
Storing The Data
After the data is calculated for each character,
Font Sizes
If the option is enabled, font sizes may be stored in the database as well to detect the size of the scanned font during scanning. When a character is iterated over during training, the current line’s font size is divided by the height of the character. All of each character’s results of this are averaged and the single number per character us stored in the database. This way, it can be multiplied by the scanned character’s height and the result will be the font size.